웹개발 및 최신 테크 소식을 전하는 블로그, 웹이즈프리
검색엔진의 robot, 크롤러(crawler)가 내 사이트에 들어와 원치 않은 정보에 접근하는 경우를 방지하기 위해서는 어떻게 해야할까요? 왜 이런일이 발생할까요?
이런 이유로 방문자 카운트에 이들 ip는 제외하도록 기능을 추가하였습니다. 그런데 이 사이트 뿐만이 아니라 다른 검색 사이트들의 robot도 제 사이트를 방문해 정보를 수집하는 것이 보이더군요... 제 사이트의 정보를 수집하는 것은 물론 홍보에도 도움이 되고 제가 원하는 바이지만(사이트를 만든지 얼마되지 않아 홍보가 필요해서 검색로봇이 절실합니다;;) 원치 않는 관리자 페이지까지 정보수집이 되어있더군요;; 이런 보안이나 Admin관련 내용등은 검색되지 않도록 조치가 필요합니다. 이런 조치는 실제 접근 가능 여부를 떠나서 나중에 문제가 되었을 때 중요한 사실 증거로서 효력을 발휘할 수 있겠지요.
# 검색엔진의 접근을 차단하는 방법
그렇다면 어떻게하면 검색엔진(Search Engine)의 검색, 인덱싱을 차단할 수 있을까요? 아래의 방법들이 사용되고 있습니다.
쉽게 생각 가능한 방법은 바로 위 세가지가 있겠습니다. 여기서 가장 간단한 방법은 첫번째 그리고 두전째 방법이 되겠습니다. 세번째 서버사이드에 코드를 추가하는 방법 역시 생가해볼 수 있을 것이나 이 부분은 시간이 많이 들고 중간에 header 정보들... ip 혹은 user-agent 등을 바꾸어 접속하면 계속해서 갱신이 필요하겠죠.
! meta 태그와 robots.txt 이용하는 방법
이를 사용하면 검색엔진의 무분별한 크롤링을 하지 못하도록 도움을 줄 수 있습니다. 물론 100% 완벽할 수는 없습니다. 어찌되었건 이런 설정을 해두어도 실제로 접근이 허용된다면 의도하지 않은 상황이 언제든 나타날 수 있겠죠. 하지만 최소한의 방지는 반드시 필요하겠으며 대부분의 메이저 검색엔진에는 나타나지 않게 될 것입니다. 그럼 다음에는 실제로 어떻게 이를 사용하는지 자세하게 알아보도록 하겠습니다.
# 메타태그(Meta tag)를 활용하기 (선택 가능한 옵션 4가지)
Meta 태그를 사용하는 방법 역시 많이 사용됩니다. 일일히 페이지에 태그를 추가해야하는 번거로움이 있지만 눈에 띄기 때문에 가장 명확한 방법이죠.
간단하게 설명하면 robot, crawler는 문서를 수집하는 것과 링크를 수집하는 것 두 가지를 분류하여 정보를 수집합니다. 그렇기 때문에 두 가지 중 원하는 옵션값을 선택하여 어떤 정보를 가져가거나 못 가져가게 하도록 설정할 수 있습니다.
! user-agent 설정하기
또한 user-agent를 지정하면 특정 봇(예를 들면 구글은 ’googlebot’을 지정)만 정할하여 검색을 제어할 수도 있습니다. 다만 설정하려는 검색 로봇의 user-agent를 알아야만 사용이 가능합니다.
# robots.txt 파일 설정하기
이 파일을 만들어서(간단하게 메모장으로 생성해도 무방) robots.txt라는 파일을 생성한 후 문법에 맞게 작성한 뒤 서버 최상의 루트에만 넣어주면 됩니다. 아주 간단한 방법으로 가장 많이 사용되는 방법입니다.
위와같이 user-agent와 allow, disallow 값을 사용하여 텍스트파일에 적어주면 됩니다.
# 검색엔진의 검색결과에 인덱싱(indexing)되지 않는 방법
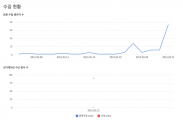
어느 날, 블로그의 방문자를 확인해 보니 비슷한 ip의 숫자가 상당수 보였습니다... 그래서 검색해보니 다름 아닌 특정 검색 사이트의 로봇 접속 ip더군요. 접근 횟수가 너무 높은 것 같아 특정 검색엔진(구글, 다음, 네이버 등등)만 제외하고는 나머지는 검색허용되지 않았으면 좋겠더군요.이런 이유로 방문자 카운트에 이들 ip는 제외하도록 기능을 추가하였습니다. 그런데 이 사이트 뿐만이 아니라 다른 검색 사이트들의 robot도 제 사이트를 방문해 정보를 수집하는 것이 보이더군요... 제 사이트의 정보를 수집하는 것은 물론 홍보에도 도움이 되고 제가 원하는 바이지만(사이트를 만든지 얼마되지 않아 홍보가 필요해서 검색로봇이 절실합니다;;) 원치 않는 관리자 페이지까지 정보수집이 되어있더군요;; 이런 보안이나 Admin관련 내용등은 검색되지 않도록 조치가 필요합니다. 이런 조치는 실제 접근 가능 여부를 떠나서 나중에 문제가 되었을 때 중요한 사실 증거로서 효력을 발휘할 수 있겠지요.
# 검색엔진의 접근을 차단하는 방법
그렇다면 어떻게하면 검색엔진(Search Engine)의 검색, 인덱싱을 차단할 수 있을까요? 아래의 방법들이 사용되고 있습니다.- Meta tag를 이용해 접근불가 정보를 robot에게 보내기
- robots.txt 파일을 생성해 수집할 수 없는 부분 설정하기
- 서버사이드에서 특정 사용자 및 로봇의 차단을 제어하기
쉽게 생각 가능한 방법은 바로 위 세가지가 있겠습니다. 여기서 가장 간단한 방법은 첫번째 그리고 두전째 방법이 되겠습니다. 세번째 서버사이드에 코드를 추가하는 방법 역시 생가해볼 수 있을 것이나 이 부분은 시간이 많이 들고 중간에 header 정보들... ip 혹은 user-agent 등을 바꾸어 접속하면 계속해서 갱신이 필요하겠죠.
! meta 태그와 robots.txt 이용하는 방법
이를 사용하면 검색엔진의 무분별한 크롤링을 하지 못하도록 도움을 줄 수 있습니다. 물론 100% 완벽할 수는 없습니다. 어찌되었건 이런 설정을 해두어도 실제로 접근이 허용된다면 의도하지 않은 상황이 언제든 나타날 수 있겠죠. 하지만 최소한의 방지는 반드시 필요하겠으며 대부분의 메이저 검색엔진에는 나타나지 않게 될 것입니다. 그럼 다음에는 실제로 어떻게 이를 사용하는지 자세하게 알아보도록 하겠습니다.# 메타태그(Meta tag)를 활용하기 (선택 가능한 옵션 4가지)
Meta 태그를 사용하는 방법 역시 많이 사용됩니다. 일일히 페이지에 태그를 추가해야하는 번거로움이 있지만 눈에 띄기 때문에 가장 명확한 방법이죠.<!-- 문서 수집 [ 가능 ] 링크 수집 [ 가능 ] -->
<meta name="robots" content="index,follow" />
<!-- 문서 수집 [ 불가능 ] 링크 수집 [ 가능 ] -->
<meta name="robots" content="noindex,follow" />
<!-- 문서 수집 [ 가능 ] 링크 수집 [ 불가능 ] -->
<meta name="robots" content="index,nofollow" />
<!-- 문서 수집 [ 불가능 ] 링크 수집 [ 불가능 ] -->
<meta name="robots" content="noindex,nofollow" />
<meta name="robots" content="index,follow" />
<!-- 문서 수집 [ 불가능 ] 링크 수집 [ 가능 ] -->
<meta name="robots" content="noindex,follow" />
<!-- 문서 수집 [ 가능 ] 링크 수집 [ 불가능 ] -->
<meta name="robots" content="index,nofollow" />
<!-- 문서 수집 [ 불가능 ] 링크 수집 [ 불가능 ] -->
<meta name="robots" content="noindex,nofollow" />
간단하게 설명하면 robot, crawler는 문서를 수집하는 것과 링크를 수집하는 것 두 가지를 분류하여 정보를 수집합니다. 그렇기 때문에 두 가지 중 원하는 옵션값을 선택하여 어떤 정보를 가져가거나 못 가져가게 하도록 설정할 수 있습니다.
! user-agent 설정하기
또한 user-agent를 지정하면 특정 봇(예를 들면 구글은 ’googlebot’을 지정)만 정할하여 검색을 제어할 수도 있습니다. 다만 설정하려는 검색 로봇의 user-agent를 알아야만 사용이 가능합니다.! 모두 검색되지 않기를 원할때
User-agent: *
Disallow: /
Disallow: /
! 반대로 모두 검색되길 원할때
User-agent: *
Allow: /
// 아래 역시 결과는 동일함
User-agent: *
Disallow:
Allow: /
// 아래 역시 결과는 동일함
User-agent: *
Disallow:
! 특정 디렉토리(폴더)만 접근을 막을때, 폴더명이 admin인 경우
User-agent: *
Disallow: /admin/
Disallow: /admin/
위와같이 user-agent와 allow, disallow 값을 사용하여 텍스트파일에 적어주면 됩니다.
# 마치면서
보안 등 중요한 정보가 담긴 경로등은 반드시 검색엔진에서 제외되어야 할 것입니다. 물론 서버쪽에서 접근을 제어하는 것이 필요하겠지만 기본적으로 검색엔진에 제외되도록 설정하는 위 방법도 필요할 것입니다. 일반적인 목적이 아닌 특수한.. 때로는 안 좋은 목적으로 검색엔진이 운용되기도 하며 여기에 사용되는 봇(bot), 크롤러 등에 의하여 피해를 입을 수 있습니다. 실제로 얼마나 중요한 정보가 쉽게 노출되는지 검색해보면 간단히 알 수 있겠습니다. 이런 일이 발생하지 않도록 철저한 준비가 필요하겠지요.아래의 글도 찾고 계시지 않나요?